反向传播
计算图Computational Graph
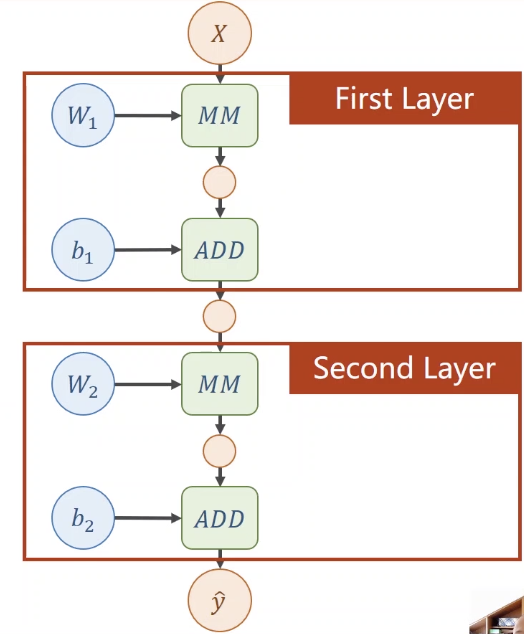
两层神经网络
$\hat{y}=W_2(W_1 \cdot X + b_1) + b_2$
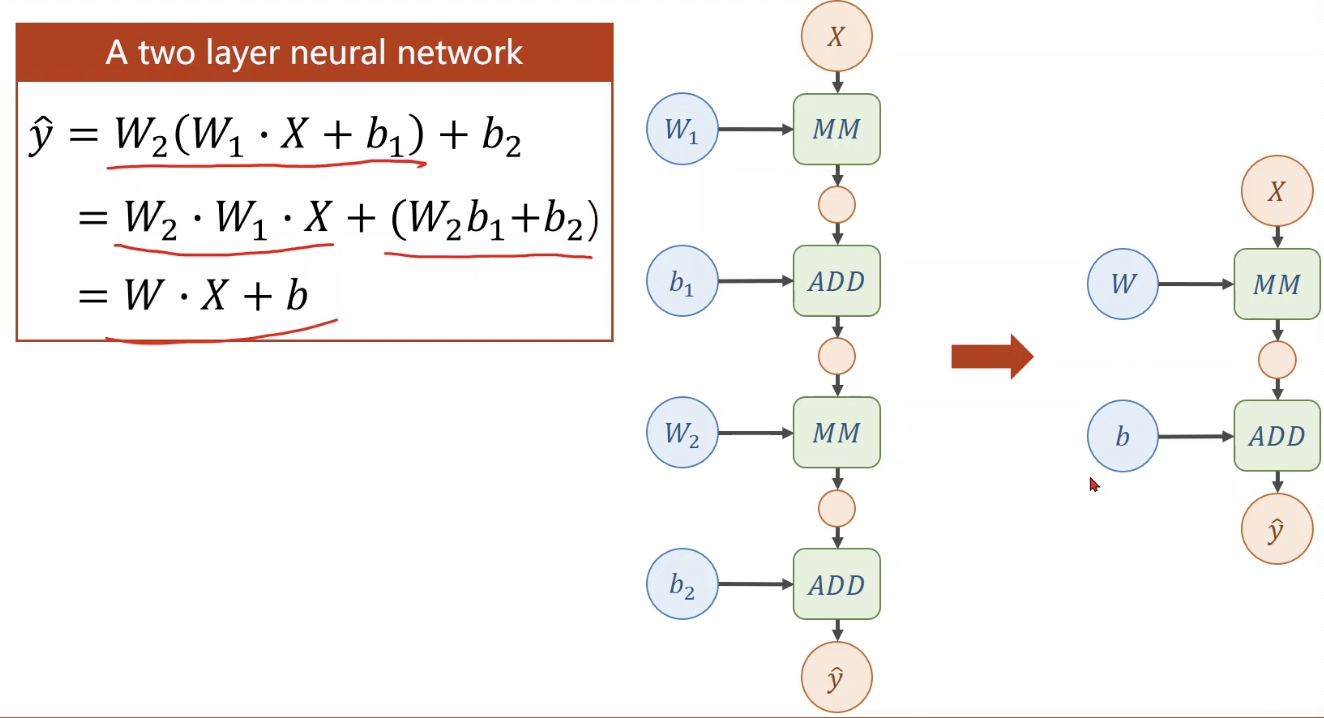
上述式子其实是可以化简的,即多层网络能找到一个等价的一层网络
如果在每一层末尾加一个非线性函数,式子变得无法化简: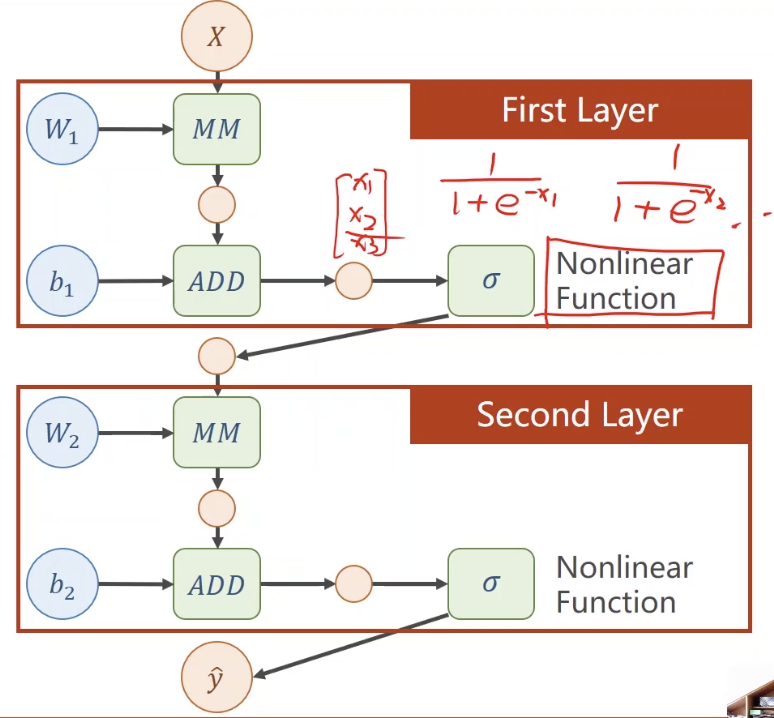
链式求导
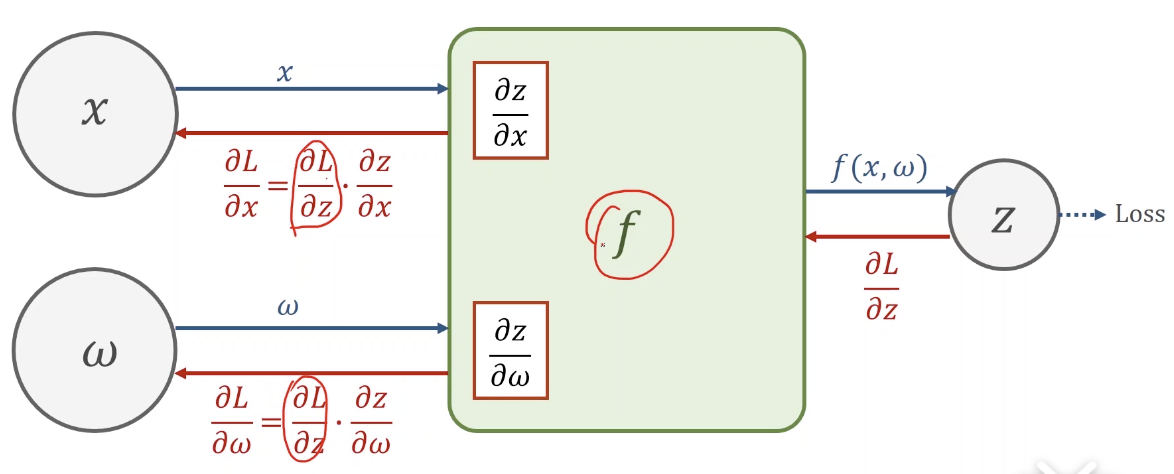
反馈过程
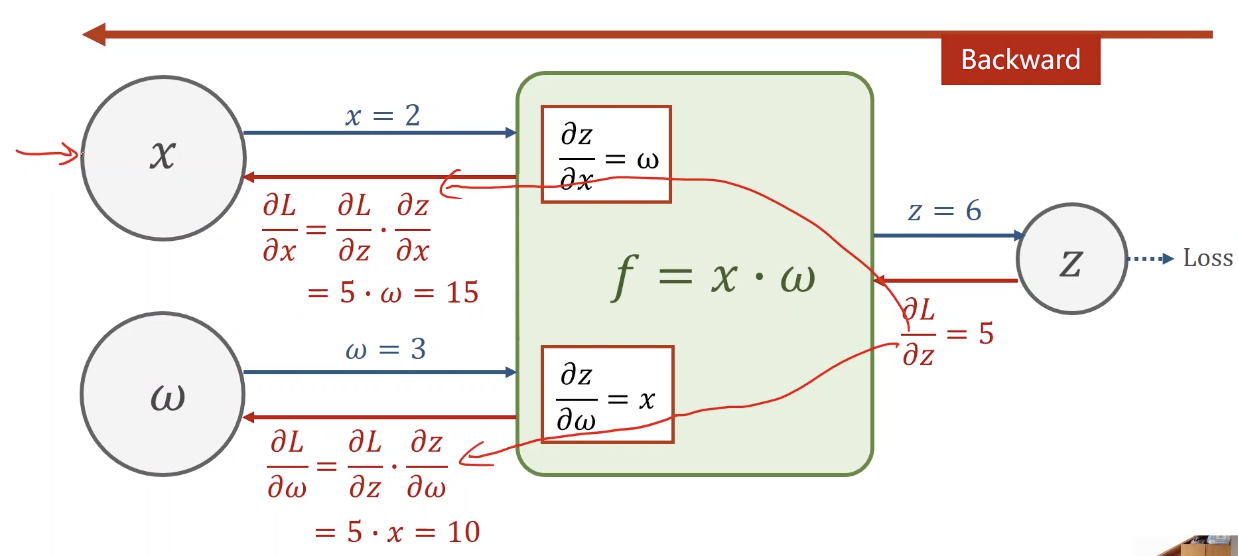
一个具体的例子,首先是一个前馈过程,再是一个反馈的过程:
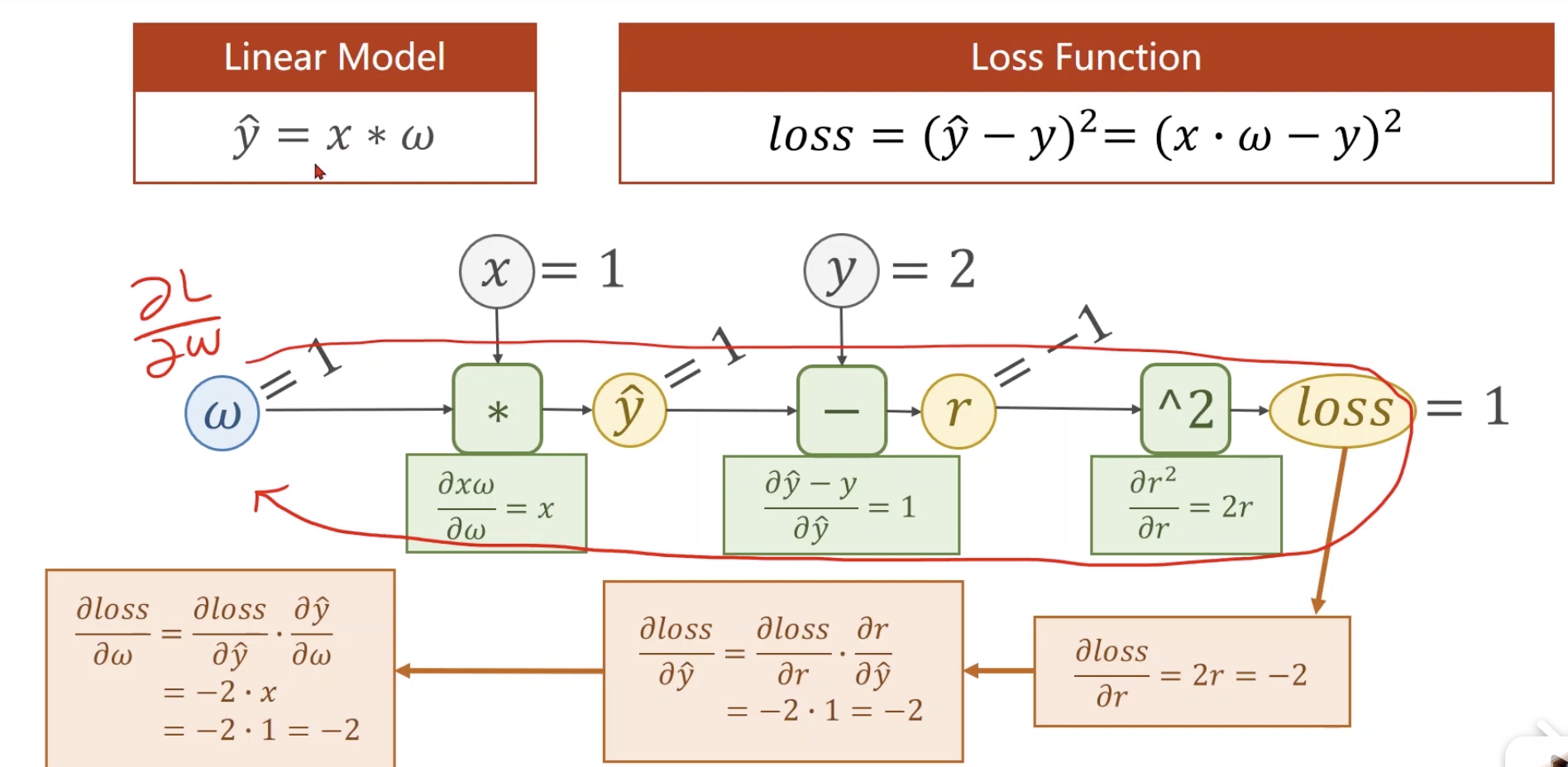
loss对要更新的参数求偏导
PyTorch实现
在Tensor中包含了数据和梯度
代码如下:
1 | import torch |
两层神经网络
$\hat{y}=W_2(W_1 \cdot X + b_1) + b_2$
上述式子其实是可以化简的,即多层网络能找到一个等价的一层网络
如果在每一层末尾加一个非线性函数,式子变得无法化简:
反馈过程
一个具体的例子,首先是一个前馈过程,再是一个反馈的过程:
loss对要更新的参数求偏导
在Tensor中包含了数据和梯度
代码如下:
1 | import torch |